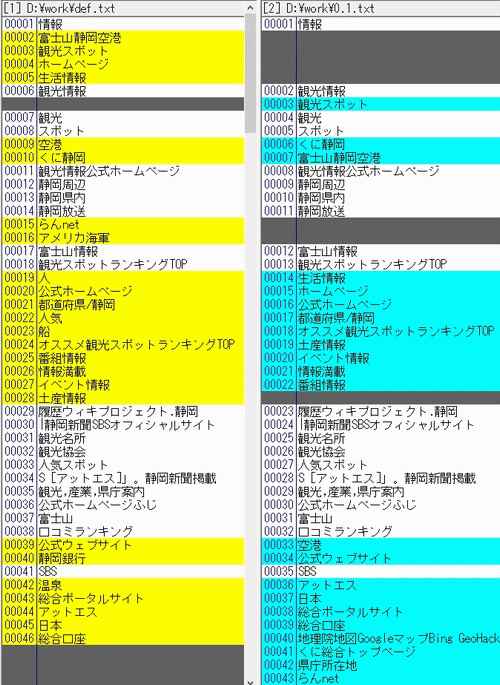
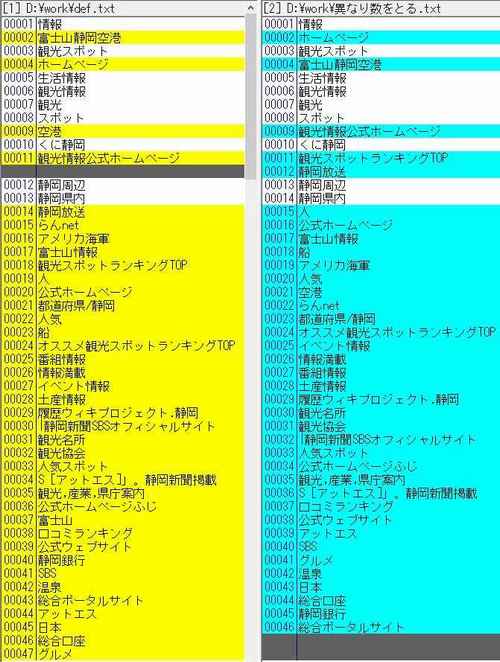
CGI化するためにシンプルに修正してみました。
どういうわけかTermExtractにUTF8で通すと結果が何も返らずEUCに変換しないとダメなので
そのようにしてみました。
何か原因があると思いますが・・・
#! /usr/bin/perl -w
use strict;
use warnings;
use Text::MeCab;
use TermExtract::MeCab;
use Jcode;
use Encode;
my $data = new TermExtract::MeCab;
my $m = Text::MeCab->new();
my $s = "全域が太平洋側気候であるが、標高差が大きいため地域による寒暖の差が激しい。冬の平野部や沿岸>部は黒潮の影響で本州の中でも非常に温暖であり、寒気の影響を受けにくいために放射冷却によって朝晩は氷点
下まで下がることがあっても、日中は10°Cを超えることがほとんどである.";
my $n = $m->parse($s);
my $t="";
my $str="";
my $txtfile="in.txt";
while ($t = $n->next) {
$str.=sprintf("%s\t%s\n",
$n->surface, # 表層
$n->feature # 現在の品詞
);
$n = $t;
}
# 何故かEUCじゃないとTermExtractの結果が返らないのでEUCに変換.
$str = &Jcode::convert($str,"euc");
# 出力モードを指定
# 1 → 専門用語+重要度、2 → 専門用語のみ
# 3 → カンマ区切り
my $output_mode = 1;
#
# 「形態素解析」済みのテキストファイルから、データを読み込み
# 専門用語リストを配列に返す
# (累積統計DB使用、ドキュメント中の頻度使用にセット)
#
my @noun_list = $data->get_imp_word($str,'var'); # 入力が変数
#my @noun_list = $data->get_imp_word("in.txte"); # 入力がファイル
#
# 専門用語リストと計算した重要度を標準出力に出す
#
foreach (@noun_list) {
# 日付・時刻は表示しない
next if $_->[0] =~ /^(昭和)*(平成)*(\d+年)*(\d+月)*(\d+日)*(午前)*(午後)*(\d+時)*(\d+分)*(\d+秒)*$/;
# 数値のみは表示しない
next if $_->[0] =~ /^\d+$/;
my $prt=&Jcode::convert($_->[0],"utf8");
# 結果表示
printf "%-60s %16.2f\n", $_->[0], $_->[1] if $output_mode == 1;
printf "%s\n", $_->[0] if $output_mode == 2;
printf "%s,", $_->[0] if $output_mode == 3;
}
カンマ区切りで出力してみました。
影響,太平洋側気候,平野部,沿岸部,放射冷却,°C,差,標高差,黒潮,寒暖,全域,冬,本州,地域,日,氷点下,寒気
次はCGI化してみます。